Set up High-Availability Kubernetes Masters
FEATURE STATE:
Kubernetes 1.5
alpha
This feature is currently in a alpha state, meaning:
- The version names contain alpha (e.g. v1alpha1).
- Might be buggy. Enabling the feature may expose bugs. Disabled by default.
- Support for feature may be dropped at any time without notice.
- The API may change in incompatible ways in a later software release without notice.
- Recommended for use only in short-lived testing clusters, due to increased risk of bugs and lack of long-term support.
You can replicate Kubernetes masters in kube-up or kube-down scripts for Google Compute Engine.
This document describes how to use kube-up/down scripts to manage highly available (HA) masters and how HA masters are implemented for use with GCE.
- Before you begin
- Starting an HA-compatible cluster
- Adding a new master replica
- Removing a master replica
- Handling master replica failures
- Best practices for replicating masters for HA clusters
- Implementation notes
- Additional reading
Before you begin
You need to have a Kubernetes cluster, and the kubectl command-line tool must be configured to communicate with your cluster. If you do not already have a cluster, you can create one by using Minikube, or you can use one of these Kubernetes playgrounds:
To check the version, enter kubectl version.
Starting an HA-compatible cluster
To create a new HA-compatible cluster, you must set the following flags in your kube-up script:
MULTIZONE=true- to prevent removal of master replicas kubelets from zones different than server’s default zone. Required if you want to run master replicas in different zones, which is recommended.ENABLE_ETCD_QUORUM_READ=true- to ensure that reads from all API servers will return most up-to-date data. If true, reads will be directed to leader etcd replica. Setting this value to true is optional: reads will be more reliable but will also be slower.
Optionally, you can specify a GCE zone where the first master replica is to be created. Set the following flag:
KUBE_GCE_ZONE=zone- zone where the first master replica will run.
The following sample command sets up a HA-compatible cluster in the GCE zone europe-west1-b:
MULTIZONE=true KUBE_GCE_ZONE=europe-west1-b ENABLE_ETCD_QUORUM_READS=true ./cluster/kube-up.shNote that the commands above create a cluster with one master; however, you can add new master replicas to the cluster with subsequent commands.
Adding a new master replica
After you have created an HA-compatible cluster, you can add master replicas to it.
You add master replicas by using a kube-up script with the following flags:
KUBE_REPLICATE_EXISTING_MASTER=true- to create a replica of an existing master.KUBE_GCE_ZONE=zone- zone where the master replica will run. Must be in the same region as other replicas’ zones.
You don’t need to set the MULTIZONE or ENABLE_ETCD_QUORUM_READS flags,
as those are inherited from when you started your HA-compatible cluster.
The following sample command replicates the master on an existing HA-compatible cluster:
KUBE_GCE_ZONE=europe-west1-c KUBE_REPLICATE_EXISTING_MASTER=true ./cluster/kube-up.shRemoving a master replica
You can remove a master replica from an HA cluster by using a kube-down script with the following flags:
KUBE_DELETE_NODES=false- to restrain deletion of kubelets.KUBE_GCE_ZONE=zone- the zone from where master replica will be removed.KUBE_REPLICA_NAME=replica_name- (optional) the name of master replica to remove. If empty: any replica from the given zone will be removed.
The following sample command removes a master replica from an existing HA cluster:
KUBE_DELETE_NODES=false KUBE_GCE_ZONE=europe-west1-c ./cluster/kube-down.shHandling master replica failures
If one of the master replicas in your HA cluster fails, the best practice is to remove the replica from your cluster and add a new replica in the same zone. The following sample commands demonstrate this process:
Remove the broken replica:
KUBE_DELETE_NODES=false KUBE_GCE_ZONE=replica_zone KUBE_REPLICA_NAME=replica_name ./cluster/kube-down.sh
- Add a new replica in place of the old one:
KUBE_GCE_ZONE=replica-zone KUBE_REPLICATE_EXISTING_MASTER=true ./cluster/kube-up.shBest practices for replicating masters for HA clusters
Try to place master replicas in different zones. During a zone failure, all masters placed inside the zone will fail. To survive zone failure, also place nodes in multiple zones (see multiple-zones for details).
Do not use a cluster with two master replicas. Consensus on a two-replica cluster requires both replicas running when changing persistent state. As a result, both replicas are needed and a failure of any replica turns cluster into majority failure state. A two-replica cluster is thus inferior, in terms of HA, to a single replica cluster.
When you add a master replica, cluster state (etcd) is copied to a new instance. If the cluster is large, it may take a long time to duplicate its state. This operation may be sped up by migrating etcd data directory, as described here (we are considering adding support for etcd data dir migration in future).
Implementation notes
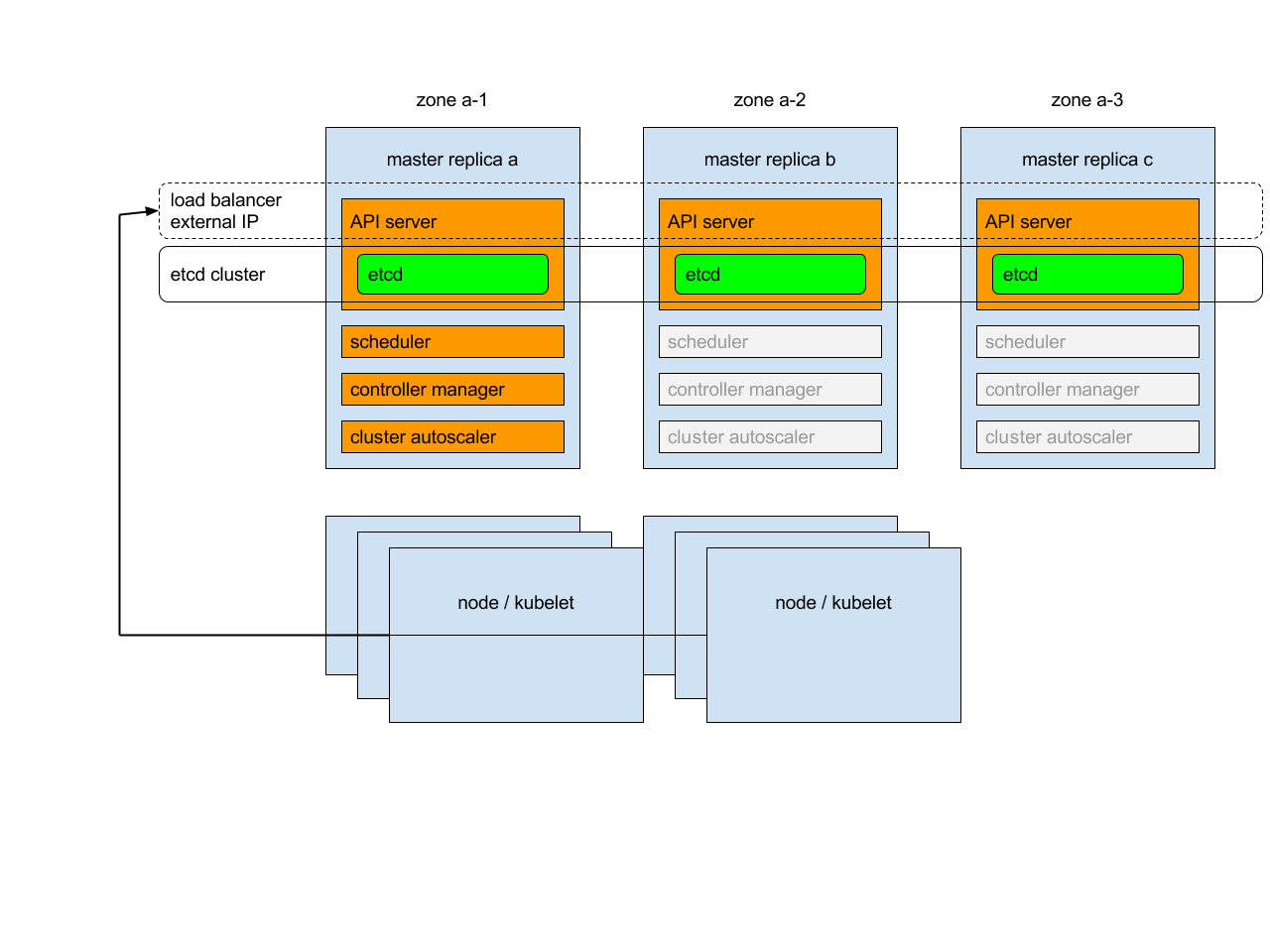
Overview
Each of master replicas will run the following components in the following mode:
etcd instance: all instances will be clustered together using consensus;
API server: each server will talk to local etcd - all API servers in the cluster will be available;
controllers, scheduler, and cluster auto-scaler: will use lease mechanism - only one instance of each of them will be active in the cluster;
add-on manager: each manager will work independently trying to keep add-ons in sync.
In addition, there will be a load balancer in front of API servers that will route external and internal traffic to them.
Load balancing
When starting the second master replica, a load balancer containing the two replicas will be created and the IP address of the first replica will be promoted to IP address of load balancer. Similarly, after removal of the penultimate master replica, the load balancer will be removed and its IP address will be assigned to the last remaining replica. Please note that creation and removal of load balancer are complex operations and it may take some time (~20 minutes) for them to propagate.
Master service & kubelets
Instead of trying to keep an up-to-date list of Kubernetes apiserver in the Kubernetes service, the system directs all traffic to the external IP:
in one master cluster the IP points to the single master,
in multi-master cluster the IP points to the load balancer in-front of the masters.
Similarly, the external IP will be used by kubelets to communicate with master.
Master certificates
Kubernetes generates Master TLS certificates for the external public IP and local IP for each replica. There are no certificates for the ephemeral public IP for replicas; to access a replica via its ephemeral public IP, you must skip TLS verification.
Clustering etcd
To allow etcd clustering, ports needed to communicate between etcd instances will be opened (for inside cluster communication). To make such deployment secure, communication between etcd instances is authorized using SSL.
Additional reading
Automated HA master deployment - design doc
Feedback
Was this page helpful?
Thanks for the feedback. If you have a specific, answerable question about how to use Kubernetes, ask it on Stack Overflow. Open an issue in the GitHub repo if you want to report a problem or suggest an improvement.
Page last modified on June 12, 2019 at 5:27 PM PST by
Restructure the left navigation pane of setup (#14826) (Page History)